

Perhaps you are moving to a new office, or like many others, realize that the cloud does not provide the cost, flexibility, and security that you need. Your CIO has tasked you with the directive to “On-Prem” your gear. With offerings such as Azure and AWS offering “on-prem” hybrid cloud solutions like Outpost, it is essential to be ready to deploy a small data center at the edge. A local colocation is another excellent option if you are looking for distributed connectivity.
I (Chris Hinkle, CEO) have seen enough disasters, and decided once and for all to put a reference architecture out there that will empower companies to choose and understand what they need so that they can make an accurate decision.
Insights on Building a Data Center
The four most important insights that I have gotten from my time in building and operating data centers are listed below. The design choices I have made for this reference architecture reflect a commitment to them. The scope of this design covers all accompanying infrastructure TO the rack, which is generally MEP and ancillary systems.
- The design must allow for people to be successful within the environment. You cannot create an unreliable infrastructure and place the burden of expectations of reliability on your IT staff to manage it.
- The design should be as safe and straightforward as possible.
- The design should be generally fault-tolerant
- The design should be able to scale reasonably
This guide will provide you with a singular reference architecture that I recommend for all corporate data centers to be successful. The recommendations come from many years of experience designing and operating data centers as an electrical engineer. For most reading this guide, we hope you provide this reference architecture to a consulting engineer to make sure that you are building to respect code and life safety so that they can follow the design and give you a great working solution.
The most important statistic I want to leave with you is that 70% of outages are due to human error per the last survey from the Uptime Institute. Even with an excellent fault-tolerant reference architecture, you need to take a hard look at your team and what you are personally either signing yourself up for or your staff. My personal feelings on the subject are that if your team can’t take a vacation or turn their phone off under planned circumstances, you are falling short of fulfilling the debt of service that you owe to make your employees successful. See this post on why digital transformation fails. We will be exploring another post about the minimum viable team you will need and core competencies to be able to operate and service these facilities.
Colocation data center teams are valuable and provide excellent service. Having staff on-site 24/7 to meet your needs and provide continuity through volatility such as disasters, staff turnover, and scalability is worth every penny, in my opinion. However, realistically, some loads can and will remain on-prem.
If you find that building and operating your own data center is not for you, we invite you to check out our amazing data center experiences with our Houston Data Center. We offer the world-leading fully managed colocation service Colo+, alongside our standard houston colocation, where we will even migrate your gear for you, take care of all rack and stack, cabling, and labelling – never come to the data center again.
Build vs Buy
Before we jump in to the main factors of building a successful data center, we should address the debate of build vs buy and what not to do when building your own facility.
The build vs buy decision will always ultimately come down to requirements. If you have an esoteric requirement that needs to be on-prem, colocation would probably not be able to help you with that. Think about edge computing – this needs to be on-site to work.
The second big point is scale. At what point with it be more commercially viable to invest in building a data center vs buying? In my experience, the threshold normally sits at around 2 -3 megawatts – anything below this and it almost never makes sense to build. This is the main reason why you never see facilities running below this number. So, when looking into building your own data center, we recommend not building below 2-3 megawatts unless there is a hard requirement that needs to be on-prem.
Adding to this, there are always developments in data center design that you, as an enterprise user, may not always be able to keep up with. This is why colocation is often such an attractive solution because providers are always on the look out for the new developments on the horizon. TRG has built a reputation by always improving on capabilities, offering state of the art double fault tolerance by design and services like ESG to make data centers greener. This helps users be automatically better aligned with their own corporate initiatives.
Cost of Building a Data Center
There are many different features to consider when it comes to choosing your data center options, and deciding on the best data center for your company’s specific needs. Take a look at some of the key factors to bear in mind.
Your Physical Footprint
Think about the physical footprint you’ll need. Once you know this, you’ll be able to get a much clearer idea of the costs involved in your colocation data center. If you’re unsure of your power requirements, this is a good place to begin.
Look at your current racks, and think about what’s coming. High density loads such as blade chassis and other devices may put you into the “Heavily Loaded Cabinet” or “Moderately Loaded Cabinet” brackets, which will affect cost.
Your Network Requirements
There is a considerable degree of variation in the costs of different network providers. Costs depend on efficiency and individual business requirements. When you look into the costs of network providers, remember that economies of scale can have a dramatic effect on pricing.
Heavy network users will therefore usually be able to access more cost effective options. For the majority of businesses, a few hundred Mbps is sufficient. This is available at around the $250/mo price point, with the option to expand as a company grows.
Service Levels
The level of service that you opt for will inevitably affect pricing, so this is another thing you’ll want to bear in mind. Many data centers offer a completely hands-off approach. While this will reduce costs, it does mean a heavier workload for your own team.
If you’d like the support of service staff, with a fully managed service and options such as remote hands available, you will likely be looking at a slightly higher price point. However, the experience offered will be far superior, and your team will have more time to focus on other tasks.
Colocation Cost Components
Some data centers come with hidden costs, so keep an eye out for these. Typically these costs might include cross connect fees, additional packages such as remote hands and extra network costs that you may not have considered. When added together, these can really bump up the price of the data center. For this reason, fully managed data centers can often prove more cost-effective in the long run.
Why Most Data Centers Suck
Having toured and audited more than 300 data centers, I find that corporate data centers get built-in odd ways. Some are “bought together” piece-meal by IT managers with no electrical or mechanical experience – they just buy and throw components at the problem. MEP Engineers specify some, and the data center is just another “feature” of that building.
Unfortunately, neither usually gets it right. I will cut IT Managers here some slack because data centers are a particular multi-disciplinary approach in engineering that is just not part of their job description. Many organizations falsely believe that a PE after someone’s name qualifies them to design data centers – and the answer is not necessarily.
I would argue that the volts and amps portion of the data center design is the easy part. The reliability engineering, an understanding of the system’s performance under various conditions, and operational insight as to the intent of the design, is the most challenging portion that comes only with experience.
Unfortunately, we find that often just because it draws amps or blows air, a regular MEP engineer may feel qualified to specify data center design – which can lead to under-performance.
To compound the issue further, these poorly designed data centers are 100% code compliant. Code is primarily about life safety, not business performance, so it is perfectly reasonable to spend a lot of money building a horrible data center from an Uptime perspective.
However, the value of the MEP engineer cannot be overstated. Under most circumstances, we recommend that you provide this reference architecture to your consulting engineer and ask for them to follow it and execute a design for you to meet your needs. If you ever need help or have questions, you can always reach out to me at chinkle@trgdatacenters.com, and I will be more than happy to help.
The Ultimate “DIY” Data Center
The design we propose can quickly scale to large data centers, but after about 1MW of IT load, more advanced designs become viable that may be executed by the most discerning engineers. It is worth noting that the sophisticated models that colocation and cloud-scale data centers employ generally improve the data center’s economics and not the overall statistical reliability. Today, the heavily leveraged designs that many cloud data centers are adopting cause overall reliability to go down significantly. (https://www.datacenterdynamics.com/en/opinions/enterprises-need-for-control-and-visibility-still-slows-cloud-adoption/).
The Uptime Institute provides an excellent document on this, concluding that “outages are common, costly, and preventable” (https://uptimeinstitute.com/data-center-outages-are-common-costly-and-preventable) that I encourage you to read here. The survey list resulted in the following:
On-Prem power failure, network failure, software/IT systems failure, on-premise DC failure (not power related) are the most common failures with percentages as high as 30% of people reporting each of these outages in the last year.
Steps, Considerations & Specifications for Building a Data Center
1. Electrical layout and general descriptions
We prefer dedicated and redundant FR3 fluid-filled transformers for primary utility entrances.
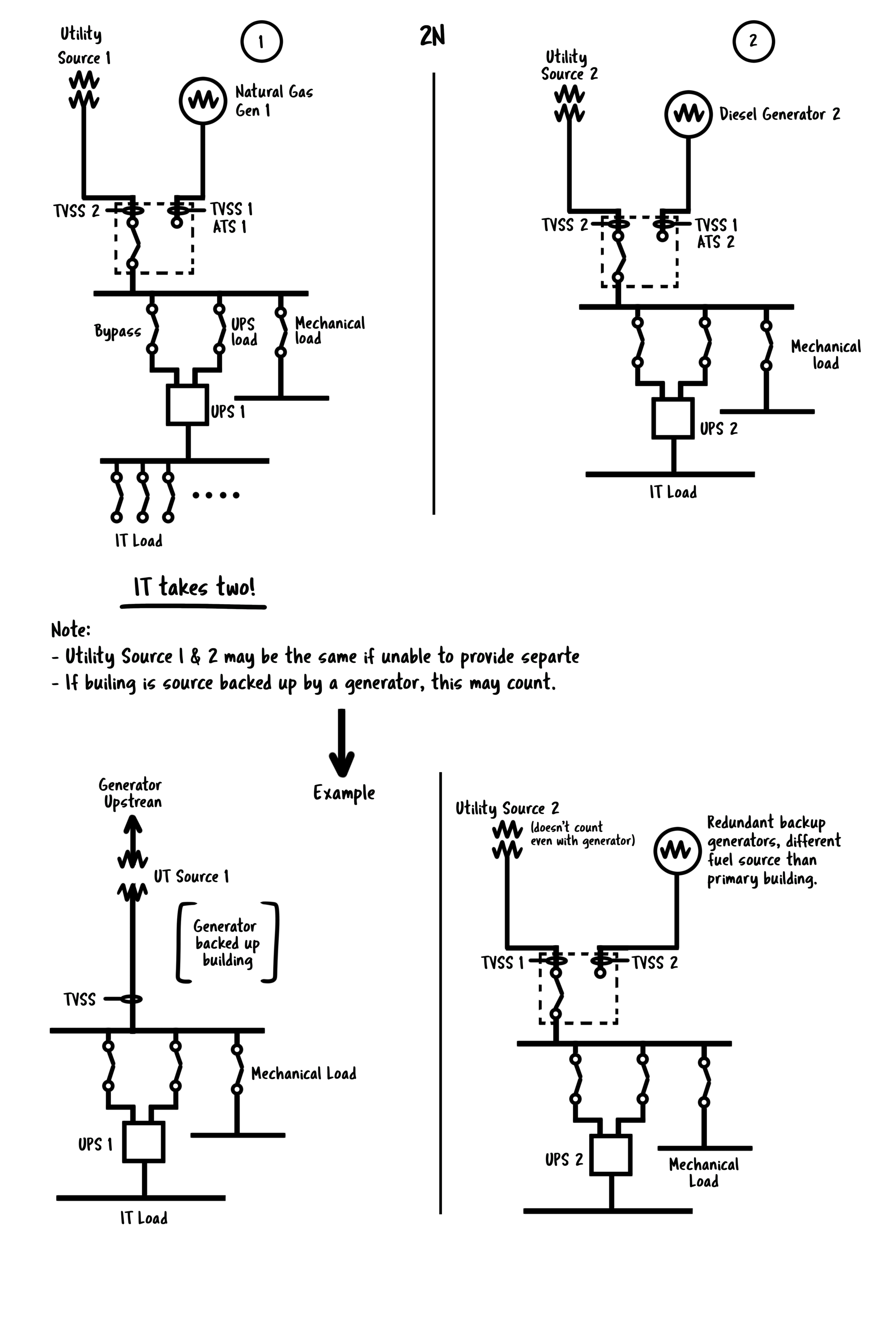
Instead of separate transformers where this is not possible, the design may accept two different feeds from the same “utility building source” as the primary utility load. Regardless of feeds from the same “utility building source”, – the central entry point to the data center shall be considered the switchgear for each leg of the 2N infrastructure. An inbound TVSS (Transient Voltage Surge Suppression System) must be on the line side of the ATS for both the utility and the generator.
The Uptime Institute does not consider utility diversity for tier ratings, nor even the presence of a utility. We would prefer to focus on building emergency backup generation redundancy at a point of demarcation that we control (the entrance to the DC and switchgear), rather than worrying about the more extensive utility system in which corporate data centers often have no control over. The vital key here is that, regardless of where we feed from for the 2N system, we have two entirely separate switchgear lineups with two different backup power generation systems (more on that soon).
The switchgear is preferred to be a two breaker pair but may accept an “ATS” with transition switch.
The transient voltage surge suppression system should have an indicator light to show the health of the device. Each leg of the 2N infrastructure must be its independent line up of switchgear, distribution, and UPS.
Sometimes we find data centers that have generators backing up the entire building; This may count as ONE generator source assuming it’s adequately designed. A UPS + distribution should feed below that to complete one leg of the 2N infrastructure. To complete the design, an entirely separate switchgear, generator, and UPS lineup should provide two truly diversely backed up cords to each rack. That entirely different system may accept the building source for its “utility source.” Still, we can’t count the same generator system twice, so we must provide a backup generator for the redundant feed.
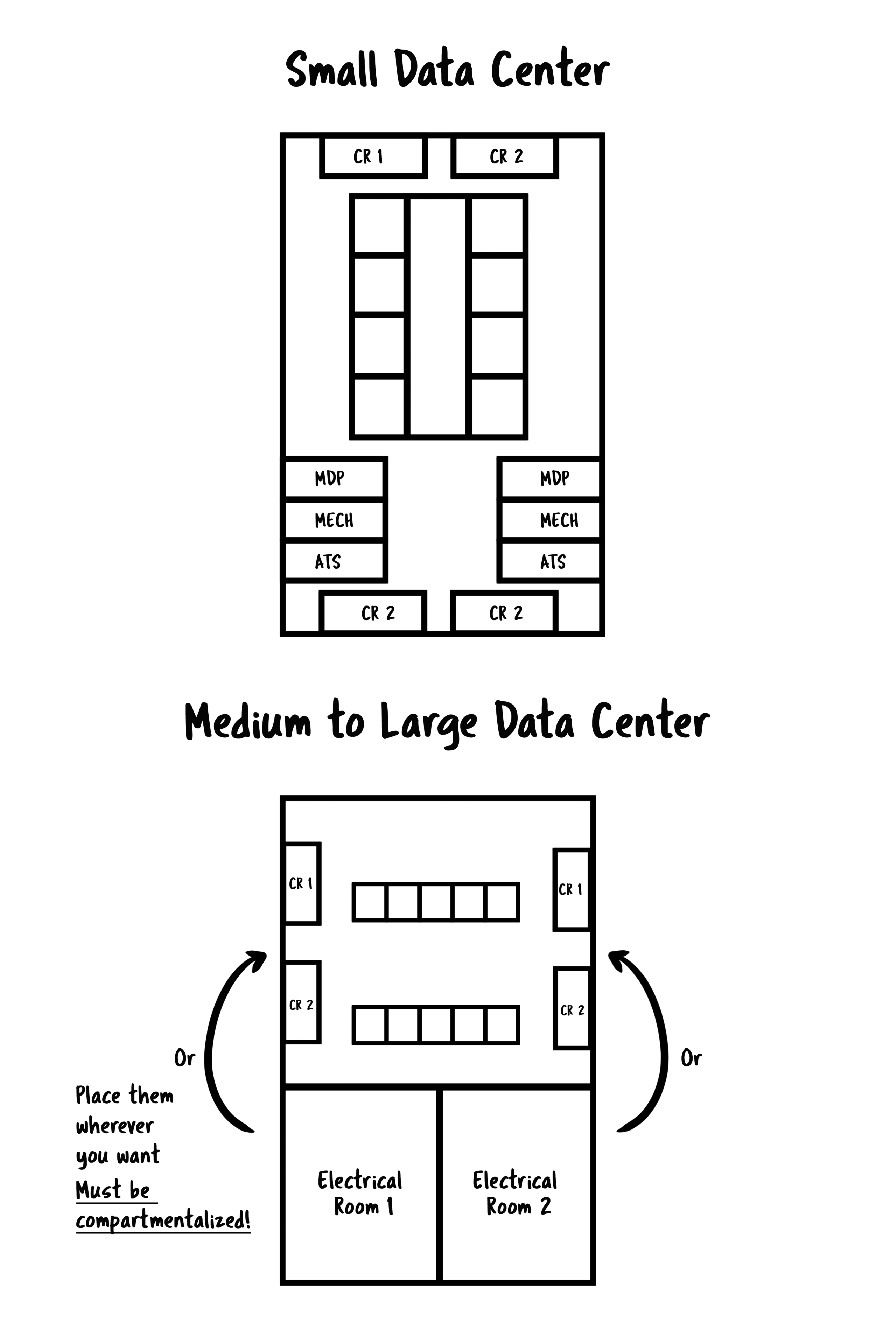
In the event of a small data center, the redundant switchgear and all critical systems may exist in the same room with the data center. Otherwise, you will want to separate, physically isolated places. In either instance, paths to and from gear, including routes out to backup generation, shall be physically diverse and isolated and will not carry down any single corridor. The physical separation between redundant feeds should include at a minimum 1 hour rated firewall.
In general, we prefer to look for physical, electrical, and logical isolation between redundant components; no paralleling, no N+1 common bus, no main-tie-main, etc.
2. Backup power and generation
Two separate generators should feed the different legs of the 2N system – one to each switchgear. The generators should not be paralleled and will act independently of one another.
Range anxiety is a real issue in smaller/remote data centers, and coordinating fuel delivery logistics for smaller facilities can be a burden. For this reason, we select diverse fuel sources for our diverse generator systems. One generator should be diesel, while the other should be natural gas.
Suppose an entire building is backed up by a backup generation system. In that case, the data center may accept that as ONE feed with TVSS and other protective measures – another N of the 2N shall be provided. The fuelling power methodology of that generation system shall be unique and diverse to the backup power of the building. For example, suppose the primary building generator system is natural gas. In that case, the backup will be diesel for the other N. If the primary building generator system is diesel – the backup will be natural gas for the other N.
The natural gas should have the capability to “rich start” in 30 seconds or less. We prefer the generator systems be physically isolated from each other. Isolation can be accomplished by placing the generators on separate sides of the building, or with sufficient distance between them. With no other options, a demising wall may be constructed to provide physical isolation — although careful with planning your airflows.
The diesel generator shall have sufficient on-site fuel for four days (96 hours) of fuel. The Uptime Institute technically requires natural gas to have a minimum of 12 hours of fuel reserve in the form of stored propane, although I do not require it. I would accept the statistical Uptime and redundancy of a two-source 2N backup generation system to specify a design for corporate data centers. The considerations of last-mile delivery challenges for small data centers must weigh against the Uptime Institute’s design theory. This break from design theory is practical for 2N systems with diverse fuel sources only.
Both generators must run for an unlimited number of hours for any outage duration. Many generator manufacturers have data center guidance, specifically, the Uptime Institute approves that, and it hovers between the continuous rating and prime rating of the generators. Proper general advice would be to not exceed 70% of the prime rating of the generator under peak conditions, fully loaded, the hottest day of the year, under a failure condition of the redundant generator system per ISO 8528-1. Generators shall be ISO 8528-1 rated.
3. Switching and distribution
Each leg of the 2N system must have its own entirely separate line up of power distribution. This distribution should be comprehensive – providing two of everything down to two cords to each rack with no intersections or common bus. Two layers of ground fault protection are preferred, so the neutral should carry at least to the second distribution level. Each Main distribution should feed its mechanical only panel and its own UPS/Datacenter distribution panel.
All inbound feeds from the exterior to the datacenter (exterior utilities, mechanical load that is outside of the room, feeds from the main building) should have a transient voltage surge suppression system in line with the main feed. The mechanical panel may also have a TVSS system in line.
My favorite gear personally for this is ASCO, and Square D. ASCO was purchased by Schneider Electric recently, and although that has caused the prices to go up, they offer rock-solid solutions at any size and price point. These two product recommendations will scale from several cabinet data centers to multi-megawatt and hyper-scale deployments very well.
https://www.ascopower.com/us/en/products/transfer-switches.jsp
4. UPS systems (Uninterruptible Power Supplies)
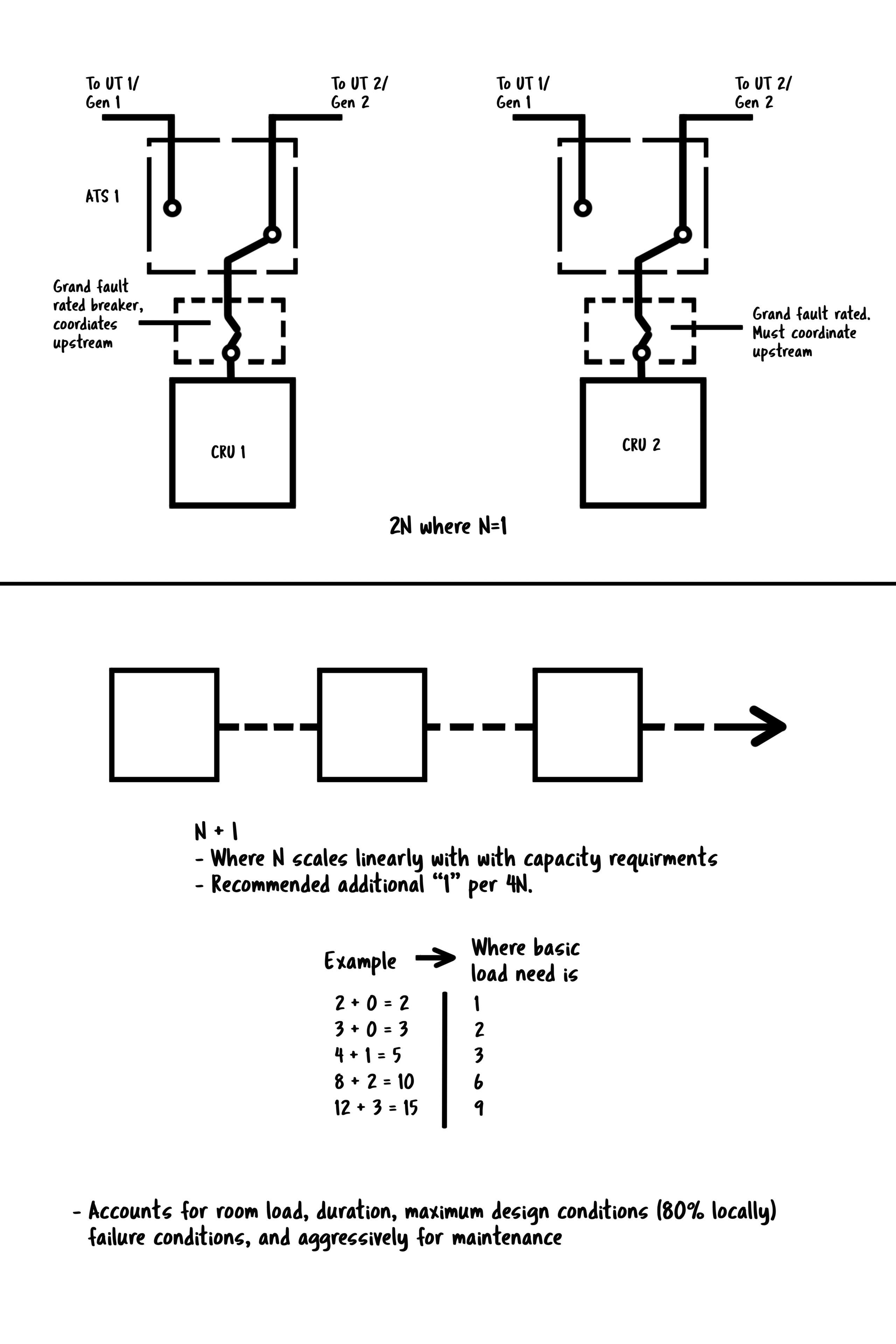
Double Online Conversion systems are the preferred system to be used. By choice, or for small data centers, in-rack UPS systems are acceptable. Each rack should have two double online conversion systems (2N), fed from each of the upstream power sources (2N). They should not parallel in any way, shape, or form. Dedicated stand-alone units should be in separate electrical rooms.
As with all other distribution elements, the units should experience no greater than 80% loaded under the worst-case failure scenario while fully loaded. There is a minimum of two separate UPS systems that are each fed by one of the two different utility feeds.
Battery cabinets can be a source of trouble for some, especially in small data centers. For a small data center, I would recommend the Vertiv Liebert series rackmount UPS. Make the investment and pop them into the individual cabinets at the right size in a 2N fashion. With two rack mount UPS per cabinet fed from different 2N feeds, losing a UPS or battery set is less “painful” under the 2N as well as the distributed architecture. When one fails, it’s less traumatic as well – you could easily keep a cold spare at the facility and just swap it out when the time comes. Batteries are the least reliable component of any datacenter.
These types of rackmount UPS systems are extremely approachable for IT staff as opposed to a large centralized system that is likely over their heads technically and a source for potential faults. I wouldn’t go as far as to say free-standing UPS are for the big boys only, but I would say up to about 100-200 kW of IT load that I would prefer to have these rack mounting units at least, beyond that it is pure preference. I have been into far too many data centers whose load changed over time held to single UPS systems, like an old storage appliance weighing them down.
Large data centers take advantage of the economies of scale with very robust free-standing units. My favorite freestanding unit is the Toshiba G9000. As you can see, these START to become relevant at around 100 kVA and then grow from there. I have used the 750 KVA G9000’s for many years and love them.
Mechanical
5. Cooling units installation and configuration
The best classic system for a reliable facility is DX systems with individual condenser feeds along separate paths to an exterior location for heat rejection. Suppose the system is a retro-fit, and they wish to utilize legacy chiller availability. In that case, install dual-coil units so the chiller is adequately considered a utility that may go away. The reliability of the chiller, whether dedicated to the data center or building, should not contribute to the system’s overall reliability under this design. While chillers do factually provide a cooling source, we consider it a utility for purposes of a reference architecture for reasons I discuss below.
I hope never to use chillers in my data center facilities designs and I will share with you some reasons why. Too often, I find that they rely on chillers as a shared resource with the building, especially in corporate data centers. Building maintenance teams are often not sensitive to the unique requirements of the data center environment. Many times, I have seen stories from end-users about the chillers shut off for maintenance with no prior notice.
Standard guidance for designing nuclear plants and submarines is to minimize the number of valves used. DX units can have as few as zero valves, while chillers require a complex symphony of valves to meet minimally viable concurrent maintainability. There has to be a good reason that this is a topic of discussion in nuclear plant design?
While fault-tolerant chiller designs exist in the industry, it is with great expense, overhead, and often extremely intricate designs. It is no wonder that outages are on the rise as chillers remain a popular option for data centers. Unfortunately, design intent and philosophy oftentimes fall to the wayside on the chopping block with short-sighted cost optimization. Having operated both types of systems, the OPEX, maintenance, and ability to sleep at night is far superior with electrically commutated fan-based DX systems.
All mechanical systems should be sufficiently elevated, and gravity fed to either interior or exterior drainage for the condensate pan. Each system should have an external leak detection sensor ringed around it in the event of water leaks. If a condensate pan must feed via a pump, the system must have a dual float off switch, be fed via redundant condensate pumps, and have an elevated floor dam built around it with leak sensors.
Vertiv Liebert series is, hands down, my favorite option for all scales for this product. They are THE industry standard and are tried and tested over many years and design cycles. The Liebert DSE is my favorite CRAC unit with its Econo-phase option and starts getting interesting when you have 300 kW+ of IT Load. For less, the Liebert DS scales you in very effectively. For very small deployments, doing an In-Row DX solution with a Liebert PDX is very cool (no pun intended) and will get you a lot of bang for your buck.
One thing I love about Liebert recently is the full conversion to electronically commutated fans. The maintenance on these things is exceptionally minimal. Change your filters and clean your condensers every three months along with an annual checkup from your local Liebert rep, and you are GOLDEN for many years.
6. Continuous cooling
The cooling system must respond to failures such that there will be no more than a 5 degree Celsius change in any fifteen minutes. Here, we must consider the compute and general thermal load’s density against the volumetric pre-cooled space of the room as well as the time to recover for these units.
Continuous cooling is pretty easy to accomplish for lightly loaded rooms. Still, for places dense for the amount of kW employed within a given number of square feet, the dynamics of heat load in the room can change exceptionally quickly even with transient failures. On small scales, we see this occur when companies begin to “outgrow” their IT closet, and on larger sizes, we see this happen with extremely high-density applications.
The time to recover may speed up via start time for generators, UPS feed the control systems for the HVAC units, and continuous supplemental power for HVAC systems via flywheel. These measures help meet the above criteria of 5 degree Celsius change in any fifteen minutes. Equipment should operate within the ASHRAE Class A1 guide for IT equipment for both humidity and temperature.
7. Network
Redundant carriers across redundant entry points and paths are required. There should be no single entry point or a common conduit. Conduit should not carry through an only path to the data center. In very small data centers, the network should terminate into separate racks. In larger data centers, the network should have two different Meet Me Rooms (MMR’s).
A network path to and through the street back to the main pop should also be redundant. Ideally, one feed is aerial, and one buried. This diversity will mitigate common fault due to construction or conversely, trucks and storm conditions. If one fiber path is aerial and one buried, the paths may overlap but are not preferred. We plan to do an article on in rack reliability and discussion for small to medium-sized businesses. Learn more about that here.
Ancillary Systems
8. Fire suppression
Dual interlock or gas-based fire suppression systems are permissible. Careful about the management of the environment with gas and VESDA, these systems are notorious for false alarms and life safety issues.
9. Building & environmental monitoring system
Switchgear, generator, UPS, and all mechanical systems (all active capacity components) shall monitor via a building management system. Environmental sensors throughout the facility provide insight into the ambient temperature. BMS shall have a daily heartbeat that will send an email to responsible parties.
Spend a lot of time here thinking about what alarms are critical and what isn’t, and get this set up properly. Then get email distribution working with the vendor of your choice (I Like ALC Controls – Automated Logic) – and have email forwarding for non-emergency and pager notifications on your phone ( https://www.onpage.com/ ) for something you feel like being woken up at 3 AM is worth it. Alarm fatigue is a real issue in the industry, so be very thoughtful about how you set this up.
10. Security systems
Security is considered an ancillary system from the perspective of reliability site engineering. Still, each system at the point of use shall be sufficiently secure to meet the organization’s overall requirements.
11. Lightning protection
UL Listed Lightning protection dictates a full building set of air terminals, to include any exterior equipment. Lightning protection is good practice in any building, including one in which a data center resides. In addition to that, any inbound feeds from exterior utilities should have transient voltage surge suppression to include utility feeds from the rest of the building to the controlled data center environment.
12. Leak protection
The datacenter is preferably underneath sufficient roofing to prevent any types of leaks. Rooftop mounted equipment and penetrations account for 70% of leaks, especially in storms.
13. Containment and air handling
Hot aisle containment is the preferred methodology for the comfort of the room and pre-cooling volumetric space for redundancy ride through purposes during transient failures. In the event of large clearance space, the containment may be partial with drop ceiling and ported return grates in the ceiling. The HVAC / CRAC Units may be ducted to the ceiling’s return and draw the hot air back that way. In the event this is not possible, a thermally secure containment system must be built with common ducting back to the HVAC systems. A common plenum hung from the ceiling and tied into a full or partial containment will work in areas with less clearance.
Hot aisle containment is also preferable because it prevents batteries and ancillary systems from being unnecessarily exposed to heat if they are in the same space, which may be the case for small data centers. The ideal operating temperature for batteries is mid 70’s, any 10 degree Celsius variation from this will cause a 50% reduction in battery life.
Alternatively, in-row cooling systems that utilize DX are acceptable and even desirable in tight areas that do not have clearance. Containment is essential here. Be careful to coordinate containment with fire protection. Many fire marshalls require either unique sprinklers in the contained space or some ability through fusible links to drop or shrink the containment in the event of a fire.
14. Single corded legacy load
Any single corded legacy load must have a point of use static transfer switch (at the rack level) that provides instantaneous transfer between redundant sources. The STS (sometimes called ATS) shall be rated to accept two separate sources that are not phase synchronized. (Tripp Lite Systems accept non-phase synchronized sourced, Vertiv does not).
If you follow these guidelines for space and power, you will have an extremely well-constructed data center. No design is infallible, and operational sustainability is highly subject to a good maintenance and operations program. We will do a post soon about good basic maintenance of a data center to know the bare minimums that you should be doing on this infrastructure.
For many, the level of cost and involvement to achieve fault tolerance is far too high, so it may be best to choose a colocation environment so that your IT team can focus on the higher end portions of the stack. As demonstrated here, the physical infrastructure is a far different discipline than the IT team.
We understand that some loads do need to be on-prem, which is why TRG is announcing that we intend to offer the world’s first fully fault-tolerant on-site colocation option for clients in our Colo+ service availability zones. To learn more about this, please reach out to sales@trgdatacenters.com
Illustrations for reference:
Looking for colocation?
For an unparalleled colocation experience, trust our expert team with three generations of experience






